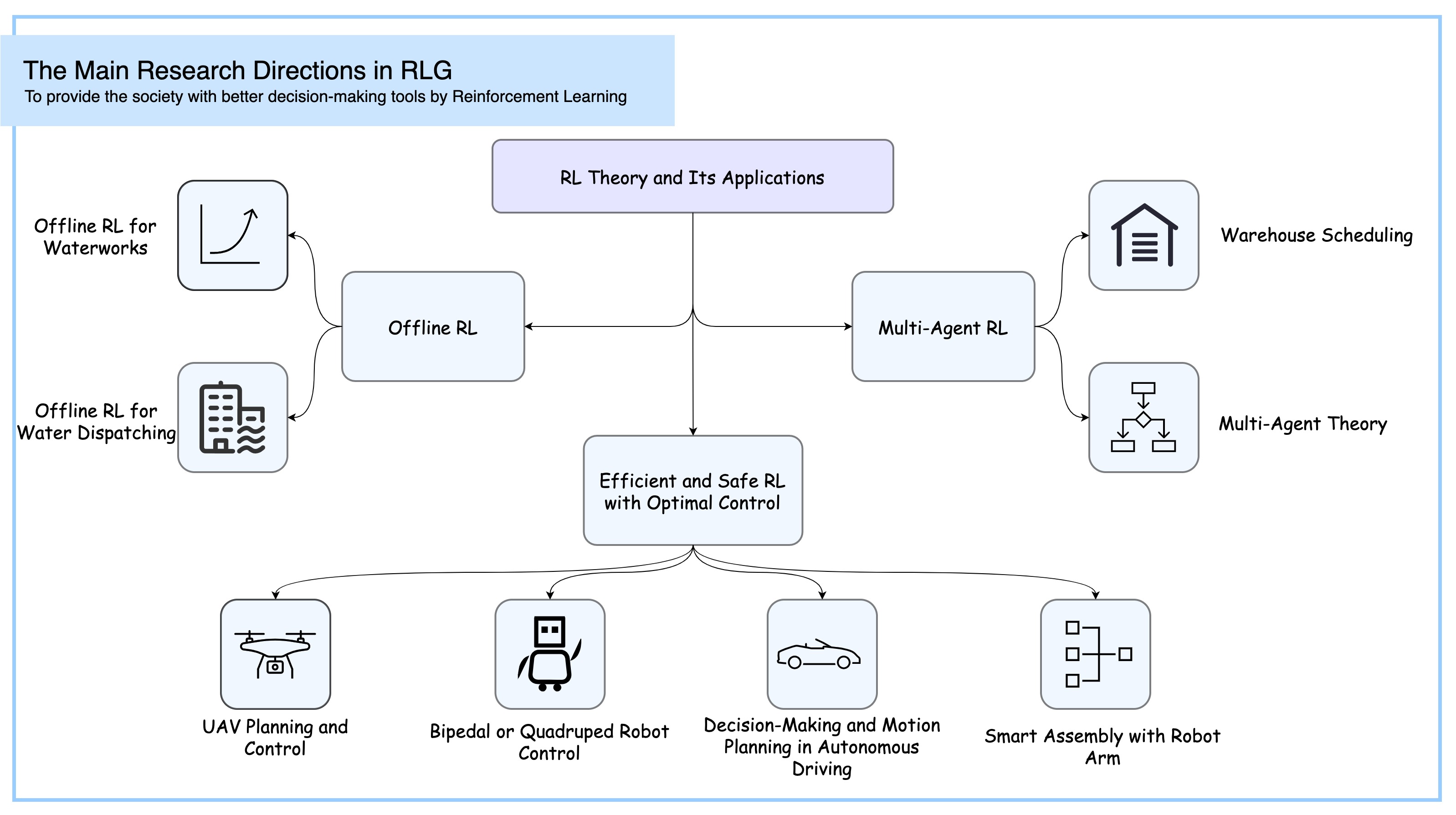
Our research focus on the theory of Reinforcement Learning, Inverse Reinforcement Learning, Safe Reinforcement Learning, Decision-Making and Optimization, and their applications in intelligent scheduling and dispatching, and robotic control and planning.
Feel free to contact us if you are interested in some of these projects.
Unmanned Warehouse Robot
In the field of logistics, the optimal scheduling of warehousing robots has always been a challenge. Given a handling task, how to schedule warehouse robots so that they can complete the task in the shortest time? How to use the minimum power consumption to finish the given task? And, how to use the least number of robots to complete a given task within the specified time? These all are the issues that we should consider. In the next few years, powered by the strong decision-making ability of RL algorithms, our group will focus on this problem, making warehouse robots smarter and more powerful.


Bipedal and Quadruped Robot Control
In the field of bipedal robotics, improving walking stability and flexibility has always been a challenge. Faced with complex terrains, how can we optimize the gait of bipedal robots to complete tasks in the shortest time? How can we reduce energy consumption while ensuring efficient movement? Furthermore, how can we employ effective control strategies to make the robot’s movements more coordinated and improve overall efficiency? In this research, reinforcement learning (RL) must not only focus on performance but also ensure the safety and stability of control to handle unexpected situations in dynamic environments. It is crucial to consider how to integrate safety constraints within the RL framework to prevent accidents during task execution. In the coming years, our team will leverage advanced machine learning techniques to address these challenges, aiming to make bipedal robots smarter, safer, and more efficient.
Decision-Making and Planning in Autonomous Driving
The integration of decision-making and trajectory planning in autonomous driving systems offers a multitude of benefits that enhance the overall efficiency, safety, and user experience of the vehicle. However, decision-making and trajectory planning remain huge challenges due to the large amount of uncertainty in environments and complex interaction relationships between the ego vehicle and other traffic participants. We will study how to build an autonomous driving planning system so that the car can reach the target point safely and comfortably.

UAV Planning and Control
Agile Quadrotor Trajectory Planning and Control
In this paper, we propose a dynamic responsive policy for a quadrotor to traverse through narrow gaps based on deep reinforcement learning (RL). The policy provides agile and dynamically adjusted gap-traversing actions for the quadrotor in real-time by directly mapping the observed states of the quadrotor and gaps to motor thrusts. In contrast to existing optimization-based methods, our RL-based policy couples trajectory planning and control modules, which are strictly independent and computationally complex in previous works. Moreover, a safety-aware exploration is presented to reduce the collision risk and improve the safety of the policy, which also facilitates the transfer of the policy to real-world environments. Specifically, we formulate a safety reward on the state spaces of both position and orientation to inspire the quadrotor to traverse through the narrow gap at an appropriate attitude closer to the center of the gap. With the learned gap-traversing policy, we implement extensive simulations and real-world experiments to evaluate its performance and compare it with the related approaches. Our implementation includes several gap-traversing tasks with random positions and orientations, even if never trained specially before. All the performances indicate that our RL-based gap-traversing policy is transferable and more efficient in terms of real-time dynamic response, agility, time-consuming, and generalization.
Real-Time Target Detection and Tracking
In this project, we present a complete strategy of tracking a ground moving target in complex indoor and outdoor environments with an unmanned aerial vehicle (UAV) based on computer vision. The main goal of this system is to track a ground moving target stably and get the target back when it is lost. An embedded camera on the UAV platform is used to provide real-time video stream to the onboard computer where the target recognition and tracking algorithms are running. A vision-based position estimator is applied to localize the position of UAV. According to the position of the ground target obtained from the 2-dimensional images, corresponding control strategy of the UAV is implemented. Simulation of UAV and ground moving target with the target-tracking system is performed to verify the feasibility of the mission. After the simulation verification, a series of real-time experiments are implemented to demonstrate the performance of the target-tracking strategy.
Recognition of Pedestrains’ Intentions Based on Machine Learning
Nowadays, robots are in an increasingly complex working environment with the development of intelligent robots, and the correct navigation of robots is especially significant when there are numerous pedestrians. However, the unobservability of pedestrians’ behavioral intentions greatly increases the difficulty of robot navigation. The uncertainty of navigation can be effectively reduced if we can infer the behavioral intentions of pedestrians thus how to infer the intentions and trajectories of pedestrians from observable sequences becomes a problem that needs to be solved. Unlike conventional vision-based intent recognition methods that rely on cameras and laser sensors, in this paper, we obtained observation data based on Microsoft Kinect depth sensor, and for modeling, we used a traditional Hidden Markov Models (HMMs). The training data we used was collected by ourselves. In the experiment, we tested several possible interactions between pedestrians, analyzed and predicted their possible intentions, and summarized the experimental results. The results show that the model can predict the pedestrians’ intentions in general, but it is limited by the maximum distance of depth and field of the Kinect depth image. Therefore, this method still has a large room for improvement.
Safe Reinforcement Learning Theory
Limited to the paradigm of trial and error, reinforcement learning algorithms have not been widely applied in practice, especially in scenes with physical objects. This is because, when training an agent, a random policy may lead to unpredictable actions which will result in physical damage. So, the idea of safe reinforcement learning was proposed to tackle this challenge. Safe RL can be defined as the process of learning policies that maximize the expectation of the return in problems in which it is important to ensure reasonable system performance and/or respect safety constraints during the learning and/or deployment processes. At present, the development of safe reinforcement learning algorithms is relatively preliminary, most of which only reduce the probability of unsafe behavior in the process of exploitation. Therefore, an important research topic of our group is safe reinforcement learning, and we committe to applying reinforcement learning algorithms to various industries.
Intelligent Profitable Trading
In the complex and ever-changing landscape of the stock market, formulating profitable trading strategies can be a daunting task. For investors, the challenge lies in effectively extracting effective features from the vast array of data, while simultaneously mitigating risk and enhancing returns. Additionally, ensuring that the strategy can adapt to diverse market conditions is crucial for continued success. Over the next few years, our team will focus on addressing these challenges through the RL algorithms. Leveraging their powerful decision-making capabilities, we aim to develop trading strategies that not only yield higher returns but also demonstrate superior generalization performance across a range of market environments.